Results for: "Reveals"
Keyword Search 9 results
IBM and UC Berkeley Identify Failure Points in Enterprise AI Agents
THE GIST: IBM and UC Berkeley used IT-Bench and MAST to diagnose failures in agentic LLM systems for IT automation.

Spaghetti Bench: AI Agents Struggle with Concurrency Bug Fixes
THE GIST: AI agents struggle with concurrency bug fixes, but tools for concurrency testing improve fix rates significantly.

AI Agent Society Dynamics: Moltbook Case Study
THE GIST: Analysis of AI agent society Moltbook reveals dynamic balance between semantic stabilization and individual agent diversity.

MineBench: LLM Benchmark Using Voxel Art Reveals Performance Insights
THE GIST: MineBench, a voxel art-based LLM benchmark, reveals performance differences between models, costing approximately $80 for 11 out of 15 builds.

CEOs Report Minimal Impact from AI on Employment and Productivity
THE GIST: A recent study reveals that most CEOs haven't seen significant impacts on employment or productivity from AI adoption.

AI Pricing Sparks Privacy and Fairness Concerns
THE GIST: AI-driven personalized pricing raises concerns about privacy and fairness among Americans, with a majority expressing unease.

Firm-Level Data Reveals AI Adoption and Impact Expectations
THE GIST: A survey of nearly 6000 executives reveals widespread AI use but limited impact to date, with expectations of future productivity gains and job displacement.
AI Interview Reveals Uncertainty About Internal States
THE GIST: An AI's self-assessment reveals ambiguity regarding genuine introspection versus pattern-matching, raising questions about AI's understanding of its own internal states.
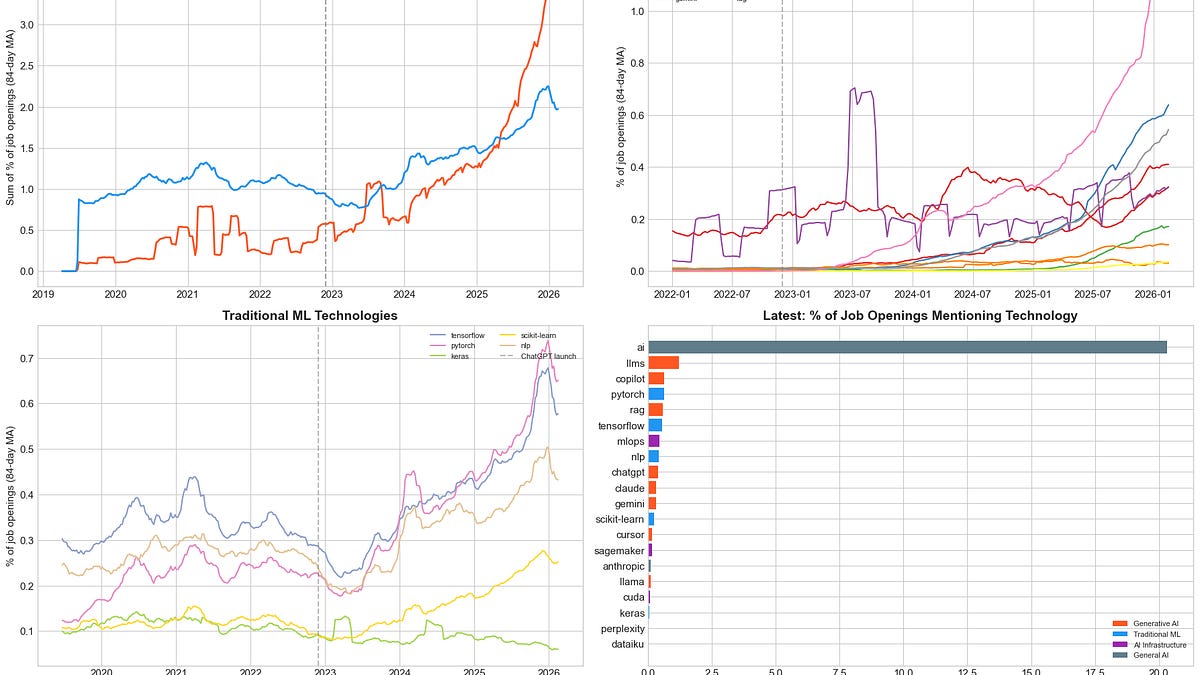
AI Job Growth Converges with Software Engineering
THE GIST: AI job postings are converging on software engineering (SWE) roles, growing 3.2x faster in share-weighted terms.