Humanity's Last Exam (HLE) Benchmark Challenges Advanced LLMs
Sonic Intelligence
HLE, a new benchmark of 2,500 expert-level academic questions, is designed to evaluate and challenge the capabilities of advanced large language models (LLMs).
Explain Like I'm Five
"Imagine you're teaching a super-smart robot everything. HLE is like a really, really hard test to see if the robot understands the hardest stuff humans know, not just what it can find on the internet."
Deep Intelligence Analysis
The development of HLE involved a rigorous multi-stage review process, ensuring question quality and difficulty. Questions were pre-tested against state-of-the-art LLMs and rejected if answered correctly, highlighting the benchmark's commitment to challenging AI capabilities. The emphasis on world-class mathematics problems underscores the importance of deep reasoning skills in AI development. The public release of HLE is intended to inform research and policymaking, providing a clear understanding of model capabilities and limitations.
However, the introduction of HLE also raises important questions about the direction of AI development. While benchmarks like HLE are valuable for measuring progress, they should not be the sole focus. It is crucial to consider the broader societal implications of AI and ensure that development aligns with human values and goals. The challenge lies in creating benchmarks that not only assess technical capabilities but also promote ethical and responsible AI development.
Impact Assessment
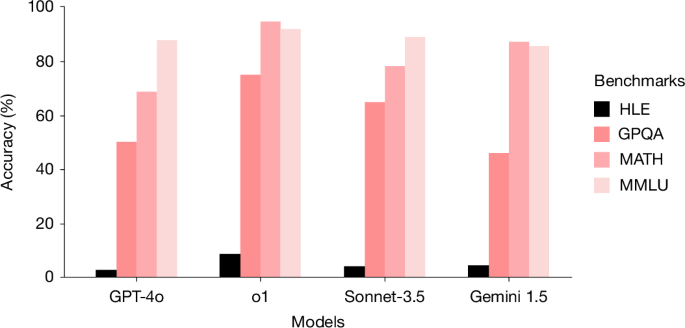
Existing benchmarks are becoming saturated as LLMs improve, limiting the ability to measure AI capabilities accurately. HLE provides a more challenging evaluation to assess the rapid advancements in LLMs at the frontier of human knowledge.
Key Details
- HLE contains 2,500 questions across subjects like mathematics, humanities, and natural sciences.
- Questions are designed to be resistant to simple internet lookup or database retrieval.
- State-of-the-art LLMs demonstrate low accuracy and calibration on HLE.
Optimistic Outlook
HLE can drive further innovation in LLMs by pushing them to develop deeper reasoning skills and improve accuracy on complex academic questions. The public release of HLE can foster collaboration and accelerate progress in AI research and development.
Pessimistic Outlook
The difficulty of HLE may expose limitations in current LLM capabilities, potentially slowing down perceived progress in the field. Over-reliance on HLE could lead to a narrow focus on academic knowledge, neglecting other important aspects of AI development.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.





