vLLM Architecture: Achieving High-Throughput LLM Serving
Sonic Intelligence
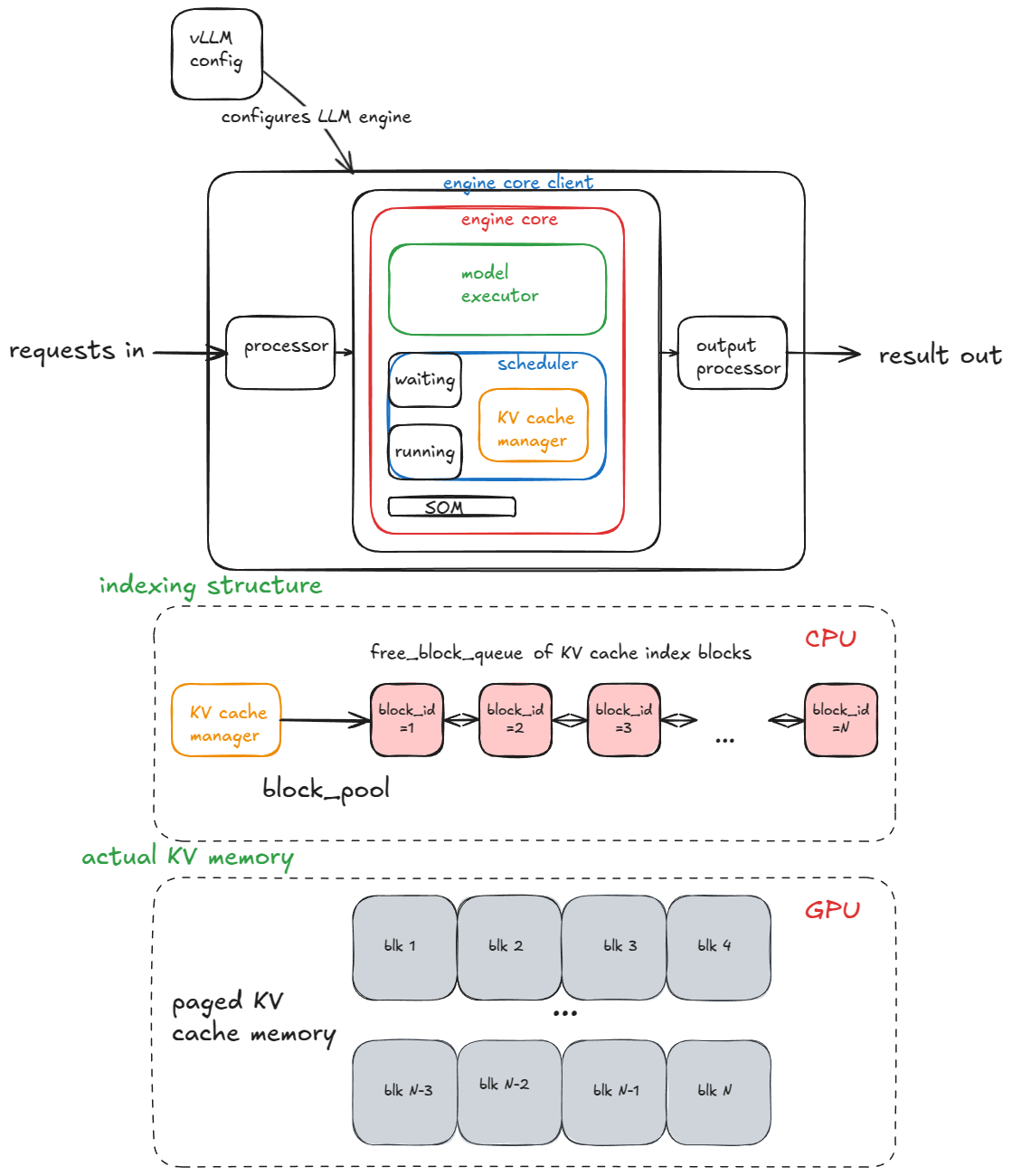
vLLM employs techniques like paged attention and continuous batching for high-throughput LLM inference.
Explain Like I'm Five
"Imagine a super-fast way to ask a computer questions, so it can answer many people at once without slowing down!"
Deep Intelligence Analysis
Continuous batching further enhances throughput by dynamically grouping incoming requests into batches, maximizing GPU utilization. This approach contrasts with static batching, where requests are processed in fixed-size batches, potentially leading to underutilization of resources. Prefix caching is another optimization technique used in vLLM, which caches the attention keys and values for the shared prefix of multiple prompts, reducing redundant computations.
The architecture of vLLM is designed to scale from single-GPU to multi-GPU and multi-node deployments. This scalability is crucial for serving large LLMs that require significant computational resources. The system also incorporates advanced features like speculative decoding, which accelerates inference by predicting the next token and verifying it in parallel. The analysis is based on commit 42172ad (August 9th, 2025).
*Transparency Disclosure: This analysis was generated by an AI language model. While efforts have been made to ensure accuracy and objectivity, readers are advised to consult with human experts for critical business decisions.*
Impact Assessment
vLLM's architecture enables faster and more efficient LLM serving, making AI models more accessible and cost-effective. This is crucial for scaling AI applications.
Key Details
- vLLM uses paged attention for efficient memory management.
- Continuous batching improves throughput by dynamically grouping requests.
- Prefix caching optimizes performance for repetitive prompts.
- Analysis is based on commit 42172ad (August 9th, 2025).
Optimistic Outlook
The ongoing development of vLLM, including advanced features like speculative decoding and multi-GPU support, promises even greater performance gains. This could unlock new possibilities for real-time AI applications and democratize access to powerful LLMs.
Pessimistic Outlook
Implementing and maintaining vLLM's complex architecture requires significant engineering expertise. The rapid pace of LLM development could also necessitate frequent updates and adaptations to the system.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.





