Results for: "llm"
Keyword Search 9 results
DeepSeek's DualPath Breaks Bandwidth Bottleneck in LLM Inference
THE GIST: DeepSeek's DualPath system improves LLM inference throughput by optimizing KV-Cache loading in disaggregated architectures.
Sleeping LLM: Language Model Learns Through Sleep
THE GIST: A new language model uses a 'sleep' cycle to consolidate memories, transferring knowledge from short-term (MEMIT) to long-term (LoRA) memory.
vLLM-mlx: Fast LLM Inference on Apple Silicon with Tool Calling
THE GIST: vLLM-mlx enables fast LLM inference on Apple Silicon, featuring tool calling, reasoning separation, and prompt caching.
AI-assert: Runtime Constraint Verification for LLM Outputs
THE GIST: ai_assert is a Python library for verifying LLM outputs against defined constraints, enabling reliable AI application development.
Open-Source AI Gateway Manages LLM Provider Access
THE GIST: AI Gateway is a self-hosted API gateway managing access to multiple LLM providers with individual client configurations.
ZSE: Open-Source LLM Inference Engine with Fast Cold Starts
THE GIST: ZSE is an open-source LLM inference engine designed for memory efficiency and high performance, boasting cold starts as fast as 3.9s.

Edictum: Runtime Governance for LLM Tool Calls
THE GIST: Edictum is a runtime governance library enforcing safety contracts for LLM tool calls, preventing harmful actions with deterministic allow/deny/redact rules.

$5 AI Agent Automates Sensors and Hardware on ESP32
THE GIST: A self-contained AI agent running on a $5 ESP32 microcontroller automates sensors, controls hardware, and creates persistent automation rules.
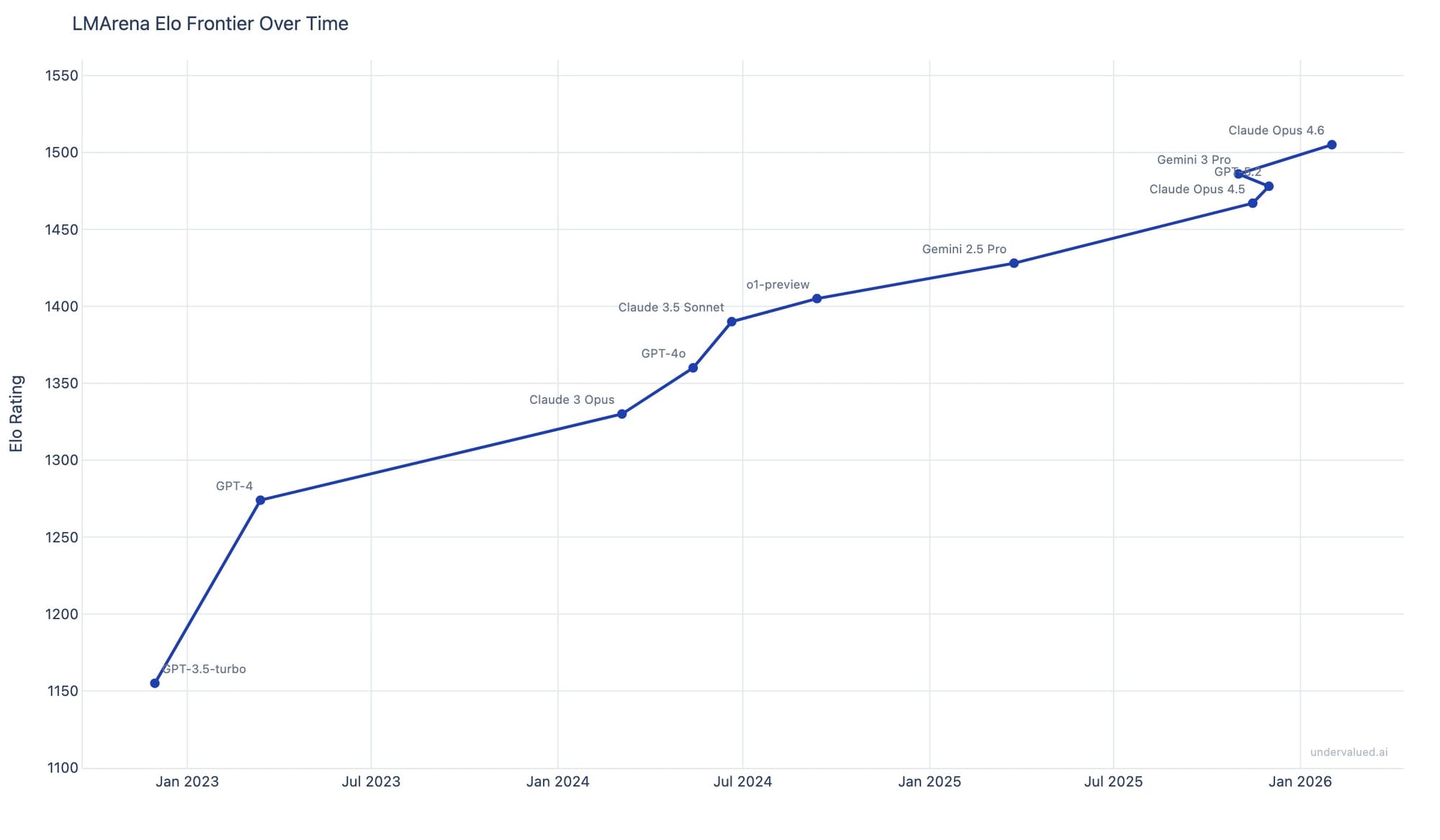
AI Intelligence Growth Slows: Hedge Fund Data Shows Plateauing Effect
THE GIST: AI intelligence gains are plateauing, with diminishing returns on training costs, suggesting a longer timeline for AI integration.