Results for: "llm"
Keyword Search 9 results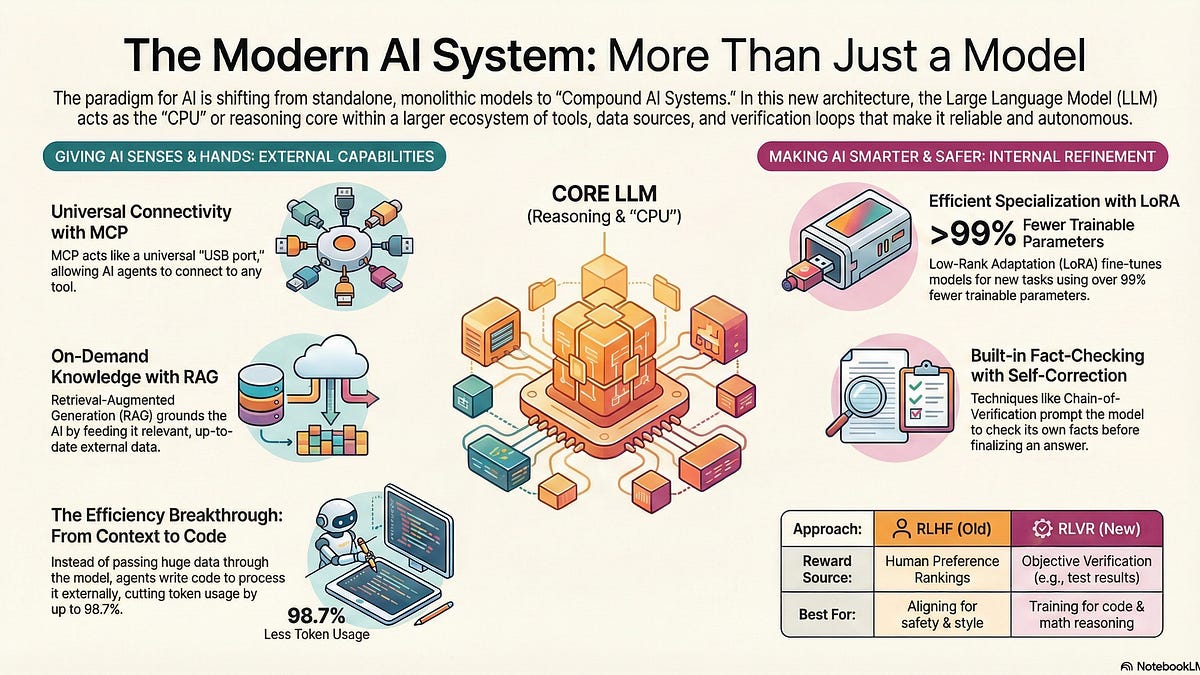
Model-Adjacent Products: Building the AI Ecosystem of the Future
THE GIST: Model-Adjacent Products (MAPs) enhance LLMs by integrating external tools and data for continual learning and autonomy.

dLLM-Serve: Optimizing Memory for Diffusion LLM Serving
THE GIST: dLLM-Serve improves throughput and reduces latency for diffusion LLM serving by optimizing memory footprint and computational scheduling.
Analyzing the Inconsistencies of LLM-as-a-Judge Evaluations
THE GIST: Inconsistencies in GPT-5.1 LLM-as-a-judge evaluations hinder reliable model comparisons, prompting investigation into the causes.

AI Drives Developers Towards Typed Languages
THE GIST: AI adoption is pushing developers towards typed languages like TypeScript due to increased reliability needs and AI-generated code volume.
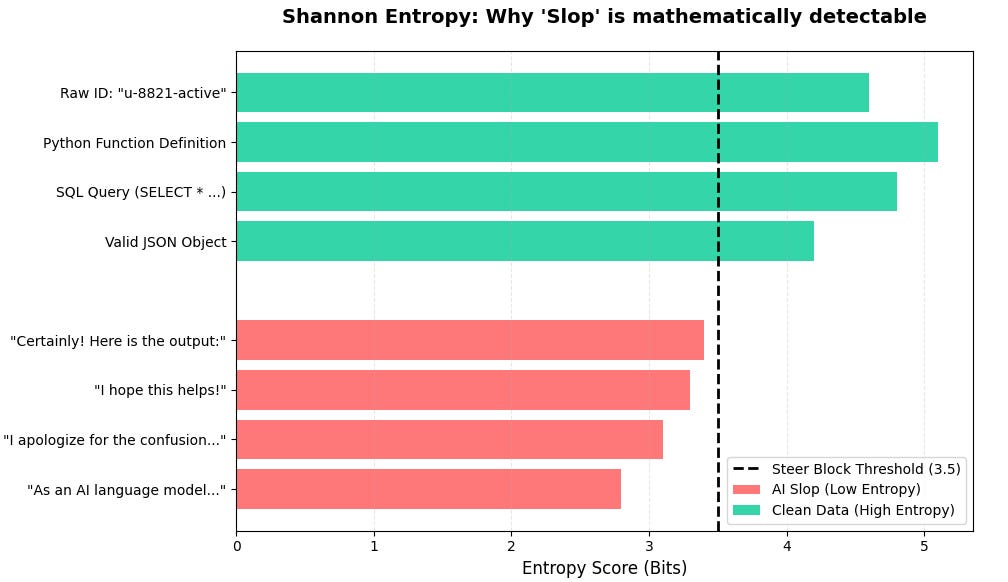
Shannon Entropy Detects and Filters AI 'Slop' in LLM Responses
THE GIST: Shannon Entropy can programmatically detect and filter verbose, low-information filler ('AI slop') in LLM responses.

LLM Agent Architectures Face Silent Failures as Complexity Increases
THE GIST: LLM agent systems experience silent failures as they grow in complexity, leading to opaque routing and blurred responsibilities.

AI Coding Assistants Decline in Quality, Exhibit 'Silent Failures'
THE GIST: AI coding assistants are reportedly declining in quality, exhibiting 'silent failures' that are harder to detect than syntax errors.

LLMs Automate GPU Kernel Optimization
THE GIST: LLMs can significantly accelerate GPU kernel optimization, bridging the gap between research algorithms and production deployment.

Can LLMs Write Great Poetry?
THE GIST: While LLMs demonstrate technical proficiency in poetry, their lack of culture raises questions about achieving true greatness.