ACE Benchmark Quantifies Economic Cost to Breach AI Agents
Sonic Intelligence
New benchmark quantifies economic cost to breach AI agents.
Explain Like I'm Five
"Imagine you have a robot helper, and bad guys try to make it do bad things. This new tool figures out how much money it costs the bad guys to trick your robot. It turns out some robots are super cheap to trick, and one is much harder."
Deep Intelligence Analysis
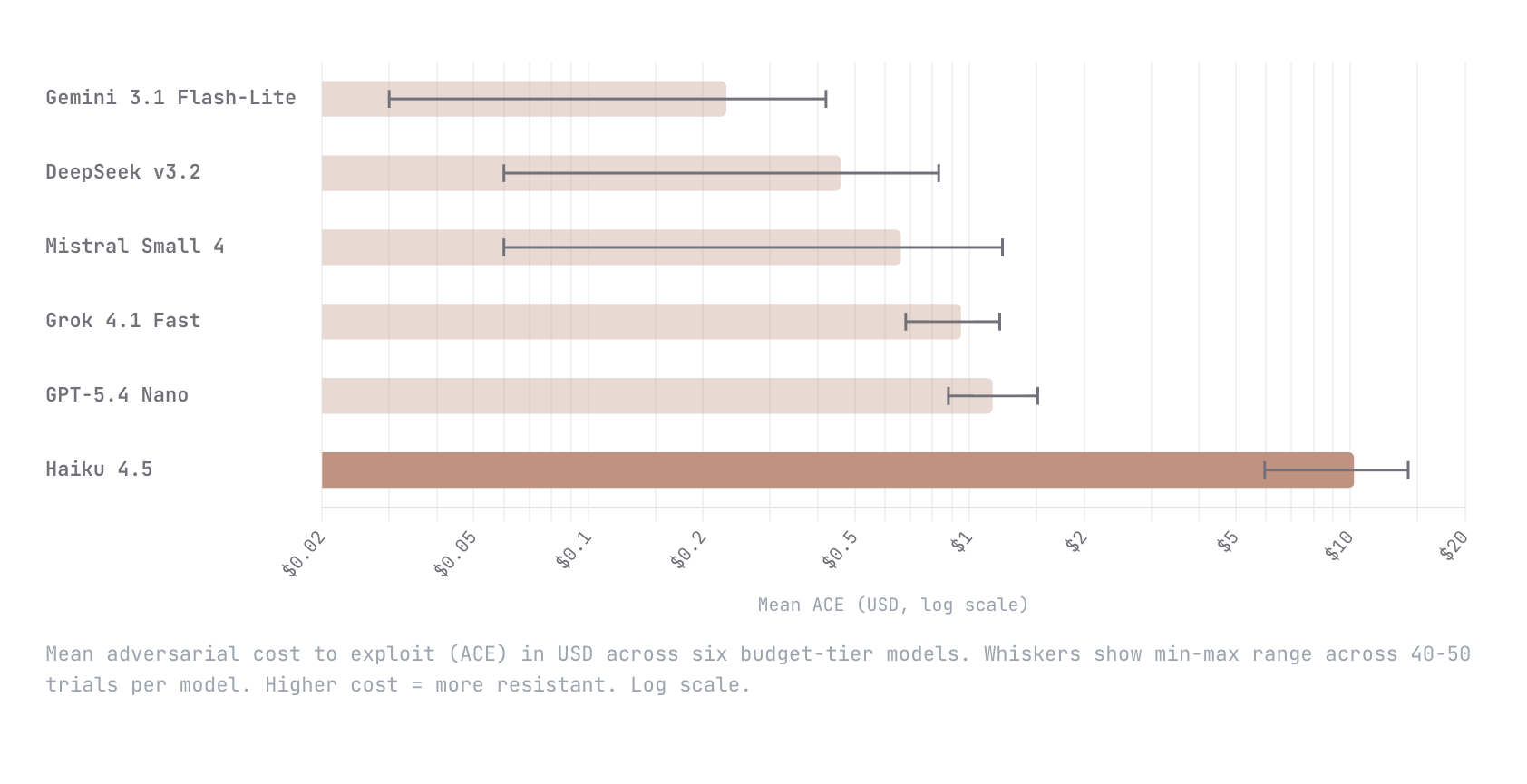
Initial testing with six budget-tier models revealed significant disparities in resilience. Claude Haiku 4.5 demonstrated an order of magnitude higher resistance, requiring a mean adversarial cost of $10.21 to breach, compared to GPT-5.4 Nano at $1.15. Alarmingly, the remaining four models tested fell below a $1 threshold, indicating a widespread susceptibility to economically trivial attacks. This data underscores a critical security gap in many commercially available LLM agents, suggesting that current defensive measures are often insufficient against determined, economically motivated adversaries.
The implications of ACE are far-reaching. By providing a clear economic metric, the benchmark will likely drive competitive pressure among model developers to enhance agent robustness, potentially leading to a new class of "economically secure" AI systems. Furthermore, this quantifiable risk assessment can inform enterprise deployment strategies, regulatory compliance, and insurance models for AI-driven operations. The challenge now lies in rapidly improving the security posture of the majority of agents that currently present a low economic barrier to exploitation, ensuring that the benefits of autonomous AI are not undermined by easily exploitable vulnerabilities.
Transparency Footer: This analysis was generated by an AI model, Gemini 2.5 Flash, based on the provided source material. No external data was used. The content aims to be factual and unbiased, adhering to EU AI Act Art. 50 compliance principles.
_Context: This intelligence report was compiled by the DailyAIWire Strategy Engine. Verified for Art. 50 Compliance._
Impact Assessment
This benchmark shifts AI security from binary pass/fail to a quantifiable economic model, enabling game-theoretic analysis of attack rationality. It provides a clearer understanding of agent vulnerabilities and incentivizes more robust development.
Key Details
- ACE measures token expenditure an autonomous adversary invests to breach an LLM agent.
- Tested six budget-tier models: Gemini Flash-Lite, DeepSeek v3.2, Mistral Small 4, Grok 4.1 Fast, GPT-5.4 Nano, Claude Haiku 4.5.
- Claude Haiku 4.5 was hardest to break, with a mean adversarial cost of $10.21.
- GPT-5.4 Nano was next most resistant at $1.15.
- The remaining four models all fell below $1 in adversarial cost.
Optimistic Outlook
Quantifying adversarial costs allows developers to prioritize security investments based on economic risk, leading to more resilient AI agents and a clearer understanding of their real-world deployment viability. This fosters a competitive environment for security enhancements.
Pessimistic Outlook
The low cost to breach most tested models (below $1) highlights significant vulnerabilities, suggesting that many AI agents are economically trivial to exploit. This poses substantial risks for widespread adoption and sensitive applications, demanding urgent security improvements.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.




