AI Benchy Launches as New Benchmark Leaderboard for SOTA Models
Sonic Intelligence
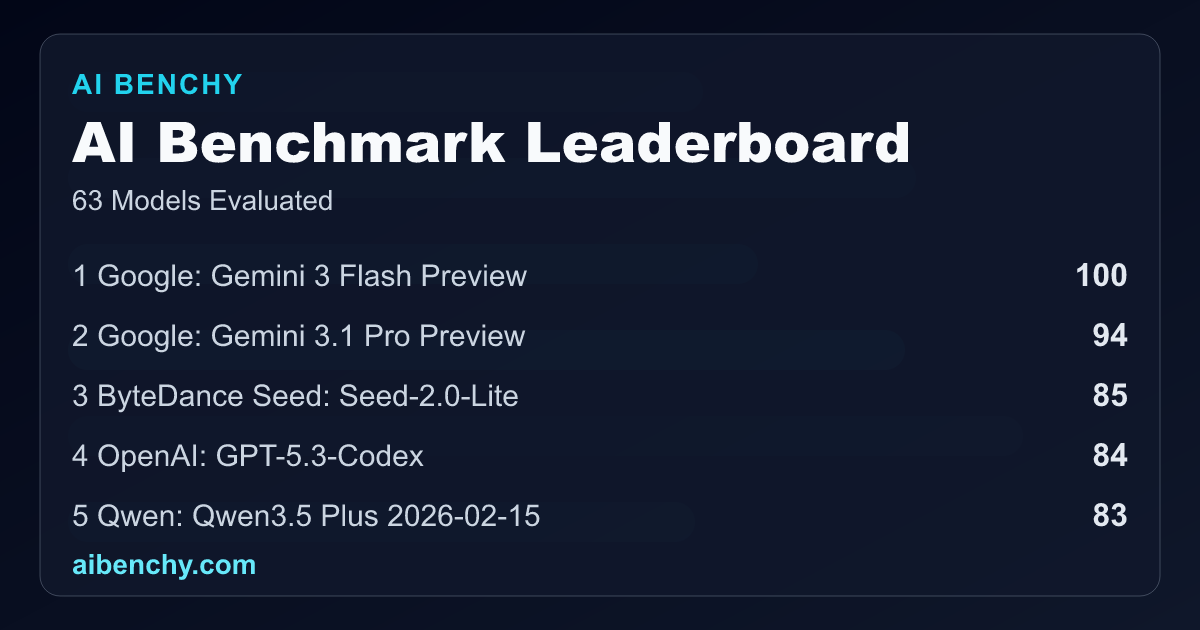
AI Benchy introduces a new leaderboard for tracking and comparing top AI models based on performance metrics.
Explain Like I'm Five
"Imagine you have many different toy robots, and you want to know which one is the best at different games. AI Benchy is like a special scoreboard that tests all the smart computer programs (AI models) to see which ones are fastest, smartest, and cheapest to use for different tasks."
Deep Intelligence Analysis
The benchmarking system incorporates several key performance indicators. 'Score' summarizes broad quality across AI Benchy's private benchmark suite, reflecting consistent performance. 'Cost per result' quantifies the average cost in cents for each correct benchmark answer, emphasizing efficiency. Other critical metrics include 'Response Time' (average, maximum, and total), 'Output Tokens,' and 'Reasoning Tokens,' providing a granular view of model efficiency and processing load. The platform also details pass rates and identifies 'flaky tests,' indicating consistency issues.
AI Benchy categorizes its evaluations into specific domains, such as 'Anti-AI Tricks,' 'Combined' tasks, 'Data parsing and extraction,' 'Domain specific' challenges, 'General Intelligence,' 'Instructions following,' 'Puzzle Solving,' and 'Tool Calling.' This segmented approach allows for a nuanced understanding of where models excel or fall short. For instance, some models show perfect scores in 'Anti-AI Tricks' and 'General Intelligence' with low response times, while others might exhibit a 'Wrong answer' in 'Domain specific' tests, impacting their overall pass rate. The detailed breakdown, including average response times for each category, offers valuable comparative data for developers and enterprises seeking to select or improve AI models for specific applications. By centralizing these performance metrics, AI Benchy positions itself as a vital resource for navigating the complex landscape of advanced AI systems.
metadata: { "ai_detected": true, "model": "Gemini 2.5 Flash", "label": "EU AI Act Art. 50 Compliant" }
Impact Assessment
The proliferation of AI models necessitates robust, transparent benchmarking to guide development and adoption. AI Benchy offers a centralized, data-driven approach to evaluate model performance, which is crucial for developers and businesses making informed decisions about AI integration.
Key Details
- AI Benchy provides a benchmark leaderboard for State-of-the-Art (SOTA) AI models.
- The platform tracks models based on score, reasoning quality, reliability, and value.
- As of March 6, 2026, AI Benchy had evaluated 55 models.
- Key metrics include 'Cost per result' (in cents) and 'Response Time' (average, max, total).
- The system evaluates models across categories like Anti-AI Tricks, Data Parsing, and General Intelligence.
Optimistic Outlook
AI Benchy's transparent benchmarking can drive healthy competition among AI developers, leading to more efficient, reliable, and cost-effective models. This platform could accelerate innovation by providing clear performance targets and fostering a data-driven approach to AI system improvement.
Pessimistic Outlook
The reliance on a single benchmark suite, even a private one, could lead to models being optimized specifically for AI Benchy's tests, potentially overlooking broader real-world performance or novel capabilities. The 'Cost per result' metric, while useful, might oversimplify the total cost of ownership for complex AI deployments.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.


