AI Commerce Lacks Standard Benchmarks, New Framework Emerges
Sonic Intelligence
AI commerce lacks standardized benchmarks, prompting a new evaluation framework.
Explain Like I'm Five
"Imagine everyone selling AI shopping robots, but no one can really tell which one is best because they all use different ways to measure. This new tool is like a fair test that everyone can use to see which AI robot is truly good at shopping, so people can pick the best one."
Deep Intelligence Analysis
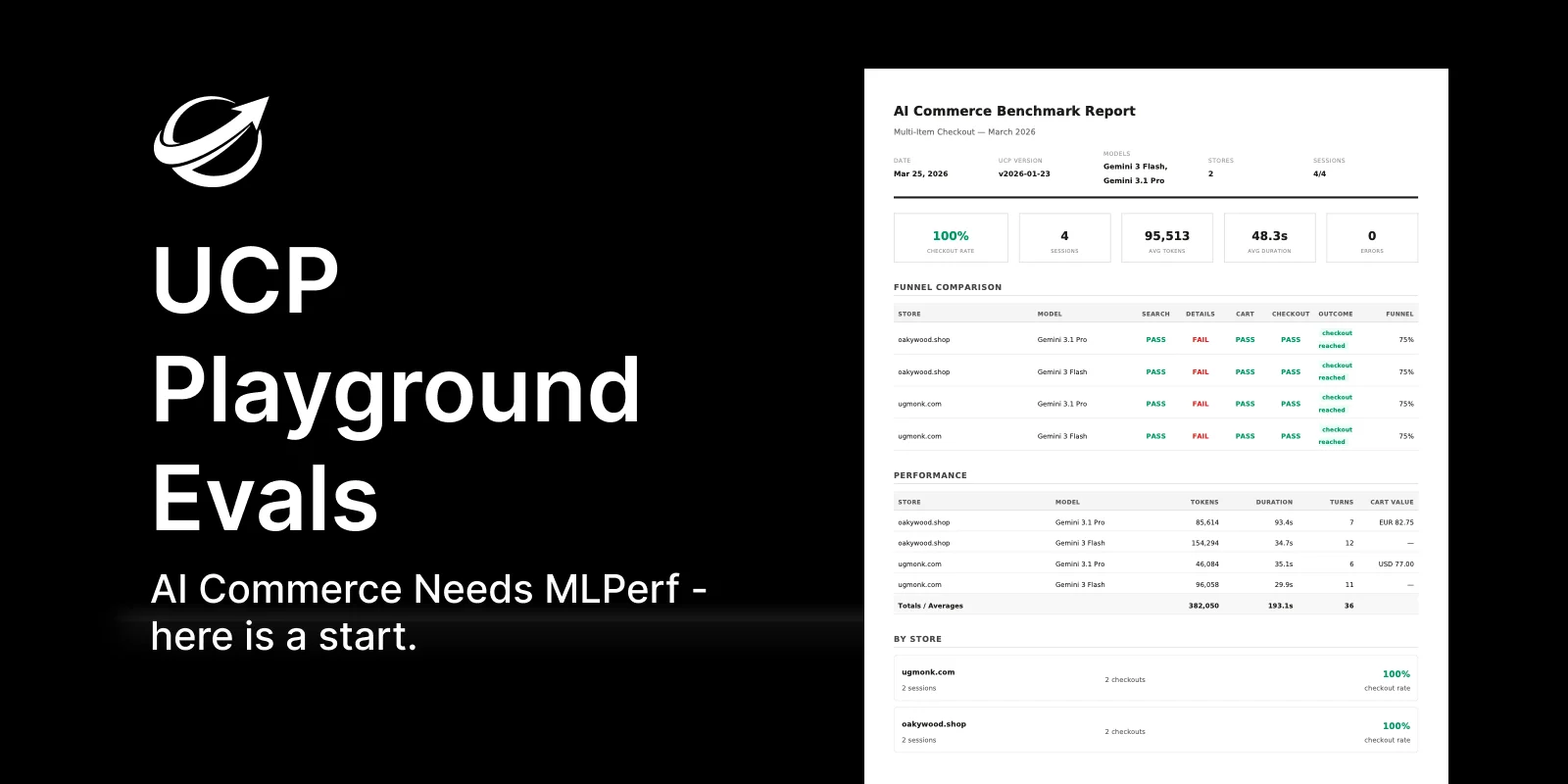
The problem stems from a fundamental "coordination problem": while the Universal Commerce Protocol (UCP) has already established itself as the open specification for agentic commerce, with over 4,500 verified stores and major retailers adopting its implementations, this technical convergence has not been matched by a shared evaluation standard. The inherent bias of internal benchmarks means a vendor cannot credibly assess its own stores or agents without questions of methodology and test conditions favoring their specific stack. UCP Playground Evals directly addresses this by providing a framework where users can define multi-turn shopping conversations and evaluate various stores and models. This system generates structured comparison reports that include critical metrics such as funnel matrices, token and duration metrics, and detailed error classifications, offering a transparent and auditable assessment.
The successful adoption of a benchmark like UCP Playground Evals is crucial for the AI commerce sector to move beyond marketing claims and into a phase of data-driven development and procurement. It will enable objective performance comparisons, drive competitive innovation based on measurable outcomes, and ultimately accelerate the widespread integration of AI agents into retail operations. Establishing a shared, auditable evaluation layer will foster greater transparency and accountability across the ecosystem, allowing buyers to make informed decisions and pushing the entire industry towards more robust and effective agentic solutions. This standardization is not merely a technical convenience; it is a foundational requirement for building trust and unlocking the full economic potential of AI-driven retail.
Visual Intelligence
flowchart LR
A[No Shared Benchmarks] --> B[Vendor Claims Unverifiable]
B --> C[Market Stagnation]
C --> D[UCP Playground Evals Proposed]
D --> E[Define Shopping Conversations]
E --> F[Evaluate Stores/Models]
F --> G[Generate Comparison Reports]
G --> H[Enable Objective Comparison]
Auto-generated diagram · AI-interpreted flow
Impact Assessment
The absence of standardized benchmarks in AI commerce creates a "wild west" scenario where vendor claims are unverifiable, hindering market maturity and trust. A neutral, reproducible evaluation layer is crucial for enabling informed purchasing decisions and accelerating the adoption of agentic commerce.
Key Details
- AI commerce currently has no shared way to verify vendor claims about agent-readiness.
- UCP (Universal Commerce Protocol) is the open spec for agentic commerce, with 4,500+ verified stores.
- UCP Playground Evals is presented as a first credible benchmark framework for agentic commerce.
- Framework defines multi-turn shopping conversations and evaluates stores/models.
- Provides structured comparison reports: funnel matrix, token/duration metrics, error classification.
Optimistic Outlook
The introduction of a standardized benchmark like UCP Playground Evals will bring much-needed transparency and comparability to the AI commerce sector. This will enable developers and retailers to objectively assess agent performance, foster innovation through clear performance targets, and accelerate the maturation and widespread adoption of agentic shopping experiences.
Pessimistic Outlook
Without broad industry adoption and third-party auditing, any new benchmark risks becoming another proprietary metric, failing to solve the core coordination problem. The challenge lies in convincing major players to submit to a common, auditable standard, which historically has been difficult in competitive, rapidly evolving markets.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.