LLM Inference Economics: Batch Sizes and Model Lab Advantages
Sonic Intelligence
LLM inference costs are shaped by batch scheduling, with model labs having a structural advantage over pure inference providers.
Explain Like I'm Five
"Imagine painting many apartments. It's cheaper to paint them all at once, but people want their apartment done quickly. Companies that make the AI models and run the computers have an advantage because they can make everything work together better."
Deep Intelligence Analysis
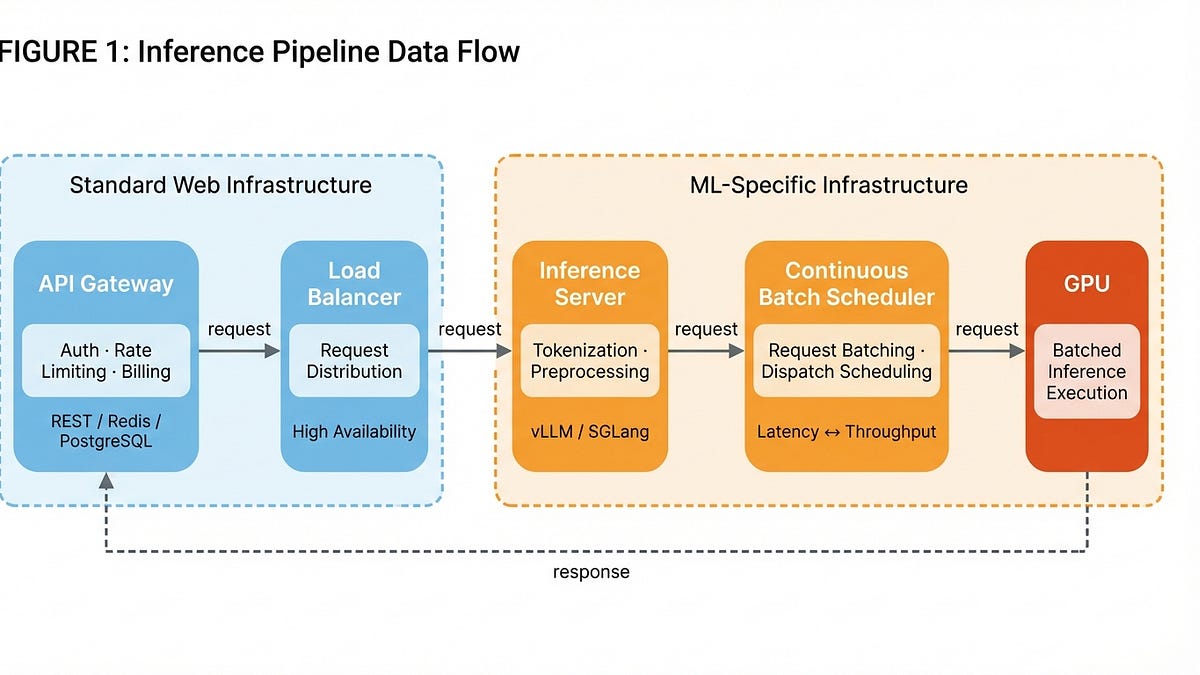
The core trade-off in LLM inference is balancing latency for individual users with throughput for the system as a whole. Continuous Batch Schedulers, like vLLM and SGLang, play a crucial role in optimizing this trade-off by bundling incoming requests into batches before dispatching them to the GPU. This batching process allows for greater GPU utilization and reduced costs but can also increase latency for individual requests.
Lechner argues that model labs, companies that both develop and deploy LLMs, have a structural cost advantage over pure inference providers. This advantage stems from their ability to optimize the entire inference pipeline, from model design to hardware utilization. Model labs can fine-tune their models to be more efficient for inference, optimize batch scheduling algorithms, and leverage their own hardware infrastructure to achieve lower costs. Pure inference providers, on the other hand, are often constrained by the models they serve and the hardware they rent, limiting their ability to optimize the inference process.
The implications of this analysis are significant for the LLM ecosystem. The structural cost advantage of model labs could lead to market consolidation, with a few large players dominating the inference market. This could stifle competition and innovation, potentially limiting customer choice and increasing prices. Pure inference providers will need to find innovative ways to differentiate themselves and compete with model labs, such as offering specialized services, focusing on niche markets, or developing novel inference techniques.
*Transparency Disclosure: This analysis was conducted by DailyAIWire's AI-driven intelligence unit. The AI model (Gemini 2.5 Flash) analyzed the provided article and generated the summary and insights. Human oversight ensured accuracy and adherence to journalistic standards.*
Impact Assessment
Understanding the economics of LLM inference is crucial for businesses building and deploying AI applications. The advantage held by model labs could reshape the competitive landscape, potentially limiting opportunities for pure inference providers.
Key Details
- Inference costs are a significant ongoing expense for companies serving LLMs.
- The inference pipeline includes an API Gateway, Load Balancer, Inference Server, and GPU execution.
- Continuous Batch Schedulers optimize latency and throughput by bundling requests.
- Model labs have a structural cost advantage in inference due to hardware ownership and optimization.
Optimistic Outlook
Efficient batch scheduling and hardware optimization can significantly reduce inference costs, making LLMs more accessible and affordable for a wider range of applications. This could accelerate the adoption of AI across various industries and drive innovation.
Pessimistic Outlook
The structural cost advantage of model labs could lead to market consolidation, potentially stifling competition and innovation in the LLM space. Pure inference providers may struggle to compete, limiting customer choice and potentially increasing prices.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.




