NVIDIA's TensorRT LLM Accelerates AI Inference with Specialized Optimizations
Sonic Intelligence
The Gist
TensorRT LLM optimizes LLM and visual generation model inference.
Explain Like I'm Five
"Imagine you have a super-smart robot that can talk and draw pictures, but it thinks very slowly. NVIDIA made a special "turbo boost" for these robots called TensorRT LLM. It makes them think and create much, much faster, especially when lots of people are asking them questions at the same time. Now, they've even shared the secret recipe for this turbo boost with everyone, so more people can make their robots super fast!"
Deep Intelligence Analysis
Recent advancements highlight TensorRT LLM's focus on pushing performance boundaries. Key developments include the implementation of Distributed Weight Data Parallelism (DWDP) for high-performance LLM inference on NVL72, optimized MoE communication over NVLink, and the integration of Sparse Attention. Performance benchmarks demonstrate significant gains, such as running Llama 4 at over 40,000 tokens per second on B200 GPUs and achieving world-record DeepSeek-R1 inference performance with NVIDIA Blackwell GPUs. The framework also provides Day-0 support for new models like OpenAI's GPT-OSS-120B/20B and LG AI Research's EXAONE 4.0, ensuring rapid compatibility with emerging AI architectures. This continuous optimization and broad model support are crucial for enterprises seeking to minimize inference latency and maximize throughput in production environments.
The strategic implications of TensorRT LLM's evolution are multifaceted. Its open-source availability is poised to foster a more collaborative ecosystem, potentially leading to faster feature development and wider integration across various AI applications. However, this also reinforces NVIDIA's ecosystem lock-in, as the optimizations are inherently tied to its GPU architecture. For organizations, leveraging TensorRT LLM becomes essential for competitive advantage in AI deployment, demanding investment in NVIDIA hardware. The continuous pursuit of inference efficiency will drive down the operational costs of AI, making more sophisticated models economically viable for a broader range of use cases, from real-time conversational AI to complex visual content generation, thereby accelerating the overall pace of AI industrialization.
Transparency: This analysis was generated by an AI model (Gemini 2.5 Flash) based on the provided source material. No external information was used.
Impact Assessment
Efficient inference is critical for deploying large AI models at scale, directly impacting operational costs and real-time application feasibility. TensorRT LLM's continuous optimization efforts, particularly its open-source transition and support for cutting-edge hardware, solidify NVIDIA's position as a foundational enabler for advanced AI deployment, influencing the economic viability of next-generation AI services.
Read Full Story on GitHubKey Details
- ● TensorRT LLM optimizes inference for LLMs and Visual Gen models.
- ● Features specialized kernels, an efficient runtime, and a pythonic framework.
- ● Achieved over 40,000 tokens per second for Llama 4 on B200 GPUs.
- ● Now fully open-source, with development moved to GitHub.
- ● Supports Distributed Weight Data Parallelism (DWDP) and Sparse Attention.
Optimistic Outlook
The open-sourcing of TensorRT LLM will accelerate innovation in AI inference optimization, allowing a broader developer community to contribute and customize. This could lead to even more efficient and cost-effective deployment of LLMs and visual generation models, democratizing access to powerful AI capabilities and fostering new applications.
Pessimistic Outlook
While powerful, TensorRT LLM's deep integration with NVIDIA hardware could further entrench a single vendor's dominance in AI infrastructure, potentially limiting competition and innovation from alternative hardware providers. Enterprises heavily invested in non-NVIDIA ecosystems might face increased barriers to achieving comparable inference performance.
The Signal, Not
the Noise|
Join AI leaders weekly.
Unsubscribe anytime. No spam, ever.
Generated Related Signals

Decoding Chatbot Failures: Six Common Patterns of AI Answer Breakdown
Six distinct patterns explain common failures in current-generation AI chatbot responses.

On-Device LLMs Power Personalized Mobile Input Methods
HUOZIIME leverages on-device LLMs for deeply personalized mobile input.

Calibrate-Then-Delegate Enhances LLM Safety Monitoring with Cost Guarantees
Calibrate-Then-Delegate optimizes LLM safety monitoring with cost and risk guarantees.
CTX Introduces Cognitive Version Control for AI Agent Continuity and Explainability
CTX provides persistent cognitive memory for AI agents, ensuring continuity and explainability.
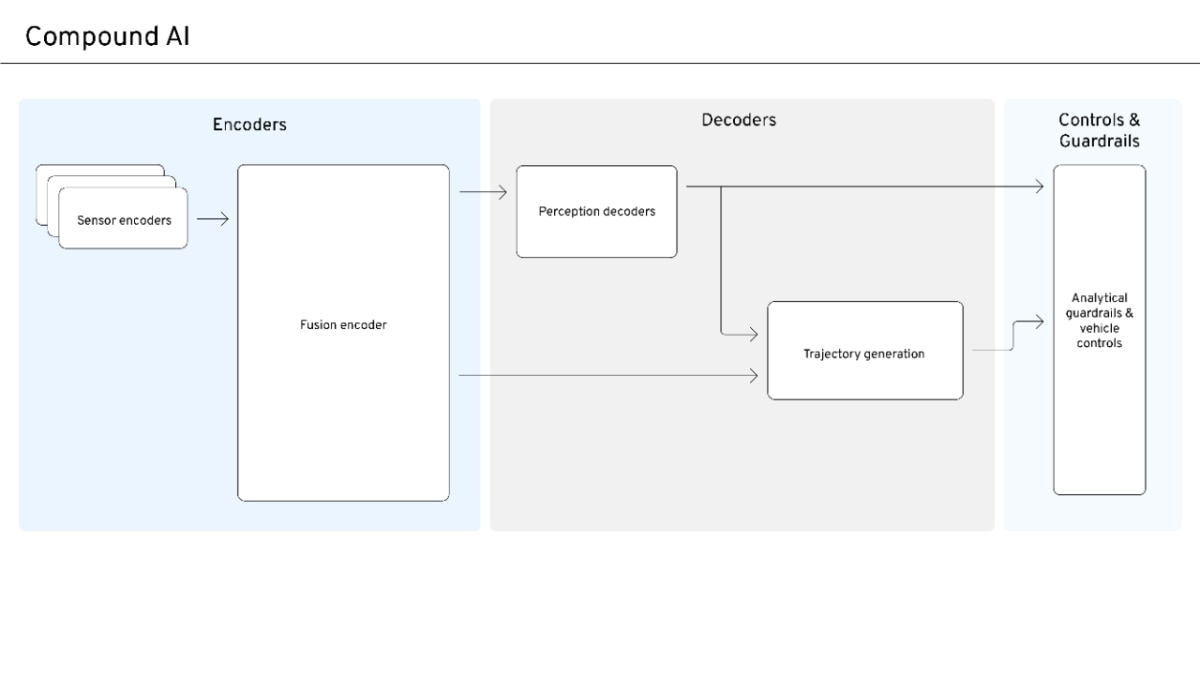
Compound AI Emerges for Safe, Scalable Autonomous Systems
Compound AI balances data-driven scale with safety and interpretability for autonomous systems.

AI Disruption Narrative Shifts from Universal Win to Competitive Reality
Early AI market optimism is yielding to a more nuanced, competitive reality.