Prompt Injection: An Architectural Vulnerability in AI Agents
Sonic Intelligence
Prompt injection is an architectural problem requiring a layered defense, not just better models.
Explain Like I'm Five
"Imagine giving a robot instructions, but someone else sneaks in bad instructions that make the robot do the wrong thing. We need to build walls and checks so the robot only listens to the good instructions and doesn't cause trouble."
Deep Intelligence Analysis
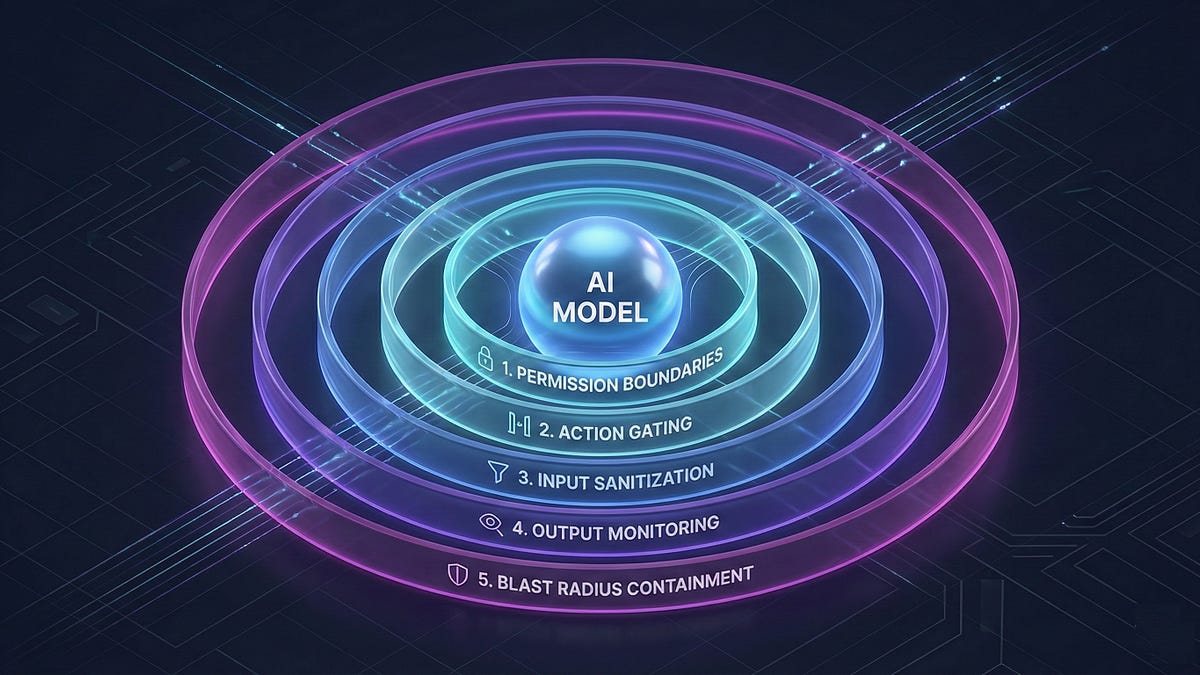
The "lethal trifecta" of tools, untrusted input, and sensitive access significantly amplifies the risk of prompt injection. The proposed solution is a five-layer defense architecture encompassing permission boundaries, action gating, input sanitization, output monitoring, and blast radius containment. This approach shifts the focus from preventing injection to managing its impact. Defense-in-depth strategies constrain autonomy, necessitating human review for irreversible actions, ultimately augmenting rather than replacing human roles.
This architectural approach is crucial for safely deploying AI agents in production environments. By focusing on a layered defense, organizations can mitigate the risks associated with prompt injection and ensure responsible AI implementation. The key takeaway is that security should be built around the model, not solely reliant on the model's inherent capabilities. This ensures that even if an injection occurs, the damage is limited and controlled, allowing for a more secure and reliable AI ecosystem.
Transparency Disclosure: This analysis was prepared by an AI language model to provide insights on AI security. The information is based on the provided source content and is intended for informational purposes only. As an AI, I am committed to responsible and ethical AI practices.
Impact Assessment
Prompt injection poses a significant threat to AI agents with access to tools, untrusted input, and sensitive data. A defense-in-depth strategy is crucial for mitigating risks and ensuring responsible AI deployment.
Key Details
- Claude Sonnet 4.6 has an 8% prompt injection success rate in computer use environments with all safeguards enabled.
- The success rate climbs to 50% with unbounded attempts.
- In coding environments, the same model has a 0% prompt injection success rate.
- A five-layer defense includes permission boundaries, action gating, input sanitization, output monitoring, and blast radius containment.
Optimistic Outlook
By implementing robust architectural defenses, organizations can safely deploy AI agents, augmenting human capabilities and redesigning workflows for increased efficiency. This approach allows for controlled autonomy, minimizing the impact of potential prompt injection attacks.
Pessimistic Outlook
Failure to address prompt injection risks can lead to catastrophic consequences, especially when AI agents have access to critical systems and sensitive information. Over-reliance on model improvements without architectural safeguards leaves systems vulnerable to exploitation.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.




