Results for: "memory"
Keyword Search 9 results
Test-Time Training: LLMs Learn from Context Like Humans
THE GIST: New research introduces test-time training (TTT-E2E), enabling LLMs to learn from context by compressing it into their weights.
SimpleMem: Efficient Long-Term Memory for LLM Agents
THE GIST: SimpleMem achieves a superior F1 score (43.24%) with minimal token cost for LLM agent memory.
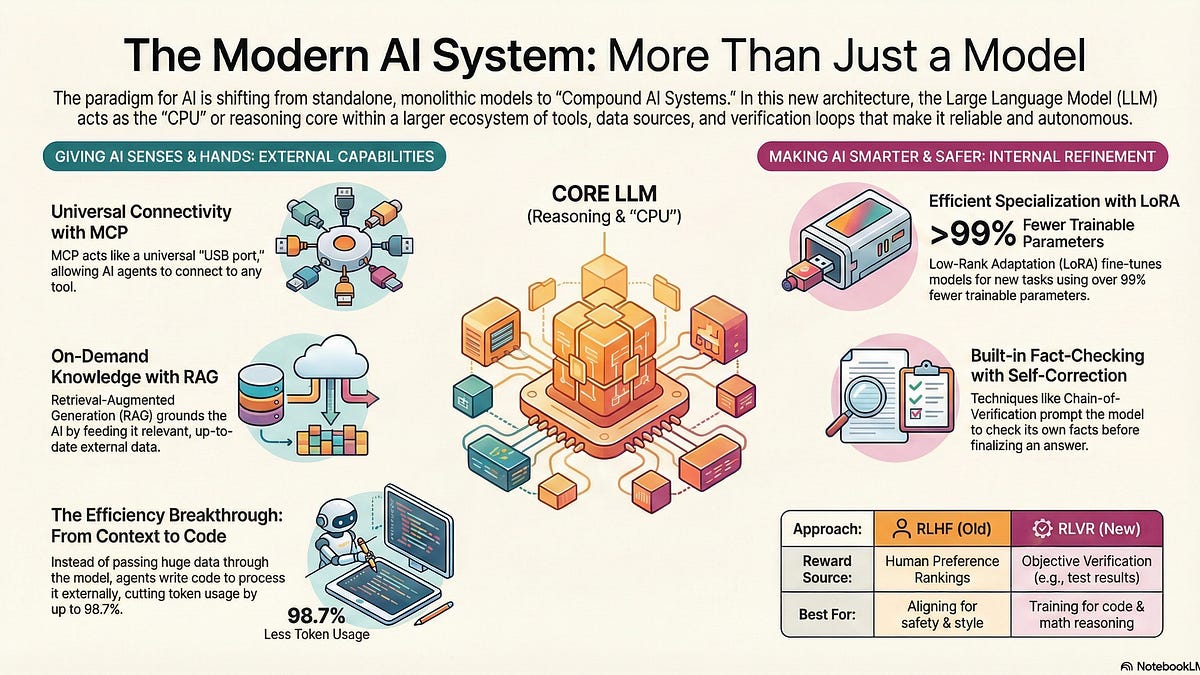
Model-Adjacent Products: Building the AI Ecosystem of the Future
THE GIST: Model-Adjacent Products (MAPs) enhance LLMs by integrating external tools and data for continual learning and autonomy.

dLLM-Serve: Optimizing Memory for Diffusion LLM Serving
THE GIST: dLLM-Serve improves throughput and reduces latency for diffusion LLM serving by optimizing memory footprint and computational scheduling.

LLMs Automate GPU Kernel Optimization
THE GIST: LLMs can significantly accelerate GPU kernel optimization, bridging the gap between research algorithms and production deployment.

MemoryGraft: Novel Attack Persistently Compromises LLM Agents via Poisoned Experience Retrieval
THE GIST: MemoryGraft introduces a novel attack that compromises LLM agents by implanting malicious experiences into their long-term memory.

AI Boom to Drive 70% DRAM Price Surge in 2026
THE GIST: AI server demand is causing DRAM prices to surge, potentially increasing by 70% in Q1 2026.

AMD Aims for Yottascale AI Compute with New Helios Platform
THE GIST: AMD unveils Helios, a rack-scale platform designed for yottascale AI, featuring Instinct MI455X GPUs and next-gen Epyc CPUs.
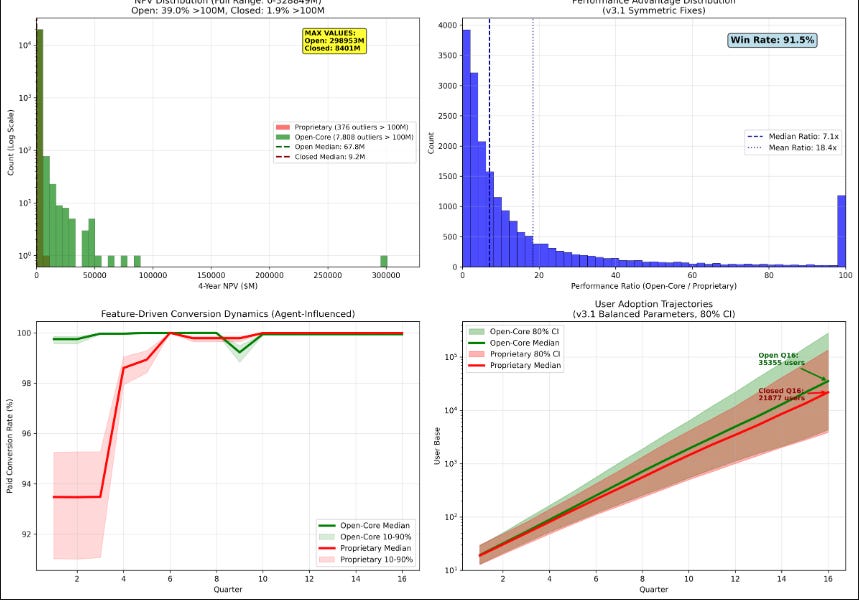
AI Agent Chooses Open Source: A 10.7x Advantage
THE GIST: An AI agent, using reinforcement learning, overwhelmingly favored open-sourcing Papr's core tech, projecting a 10.7x higher NPV.