JudgeKit Automates LLM-as-Judge Prompt Generation for Enhanced Evaluation
Sonic Intelligence
JudgeKit offers a free, research-grounded tool for generating LLM-as-Judge evaluation prompts.
Explain Like I'm Five
"Imagine you have a robot that writes stories. JudgeKit is like a special helper that creates a clear checklist for another robot to read your story and tell you if it's good or bad, based on smart rules from scientists. It helps make sure the story-writing robot gets fair feedback so it can learn faster."
Deep Intelligence Analysis
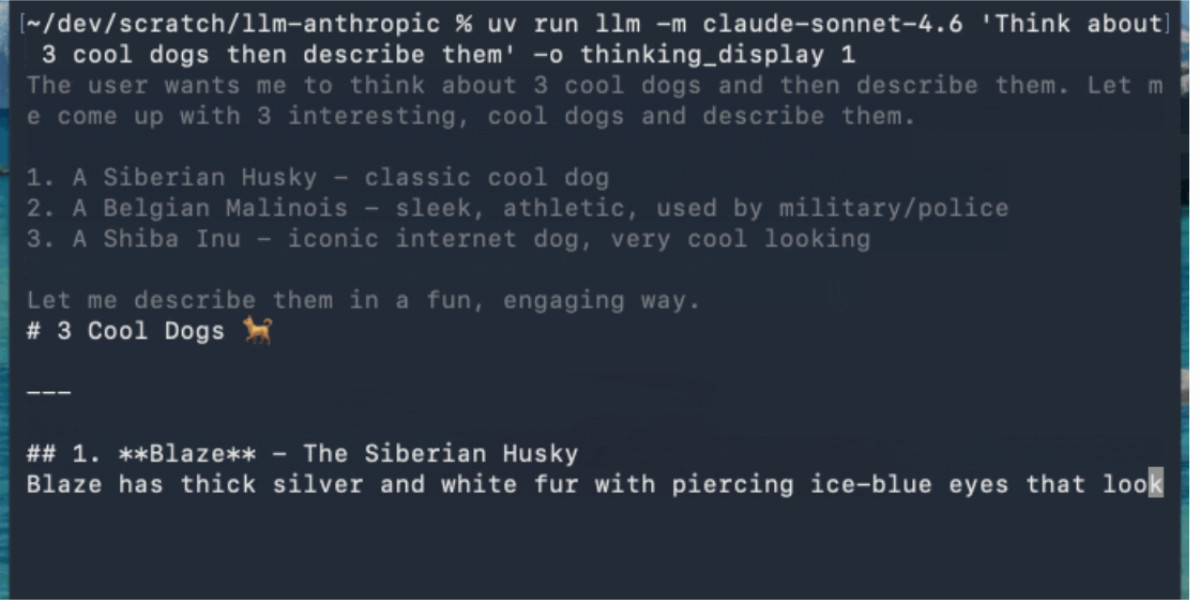
JudgeKit's feature set, including drop-in code and a 3-judge stress test, provides practical utility for developers. The support for both pointwise and pairwise evaluation modes reflects an understanding of diverse testing requirements, from assessing single responses against criteria to comparative A/B testing of different model outputs. Crucially, the emphasis on stripping PII and the 6-hour cache limit for inputs highlight an attempt to balance utility with privacy, although any data caching for evaluation traces warrants careful consideration. The inclusion of a security override within the prompt structure itself, designed to prevent untrusted data from overriding evaluation criteria, underscores a proactive approach to potential adversarial inputs in the evaluation pipeline.
The forward implications of such tools are significant. By lowering the barrier to entry for sophisticated LLM evaluation, JudgeKit could accelerate the pace of innovation in AI, enabling more rigorous testing and faster iteration cycles for model improvements. This could lead to more reliable, safer, and ethically aligned AI systems. However, the reliance on pre-defined criteria, even if research-grounded, may inadvertently constrain the discovery of novel failure modes or emergent behaviors that require more open-ended, human-centric analysis. The ultimate success of LLM-as-Judge systems will depend on their continuous refinement and validation against diverse, real-world scenarios, ensuring they complement rather than fully replace human oversight.
Visual Intelligence
flowchart LR A[Paste Trace] --> B[Pre-fill Wizard] B --> C[Review & Edit] C --> D[Select Mode] D --> E[Generate Prompt] E --> F[Stress Test] F --> G[Drop-in Code]
Auto-generated diagram · AI-interpreted flow
Impact Assessment
Accurate and consistent evaluation of Large Language Models remains a critical bottleneck in AI development. JudgeKit streamlines the creation of robust, research-backed evaluation prompts, potentially accelerating model refinement and deployment cycles by standardizing assessment methodologies.
Key Details
- JudgeKit generates LLM-as-Judge prompts grounded in published research.
- The tool provides drop-in code and includes a 3-judge stress test feature.
- It is free to use and requires no signup.
- Inputs and few-shot examples are cached for 6 hours, with PII stripping recommended.
- Supports both pointwise (single response) and pairwise (A/B test) evaluation modes.
Optimistic Outlook
This tool could significantly democratize access to advanced LLM evaluation techniques, enabling smaller teams and individual developers to implement high-quality, research-grounded judges. This standardization may lead to more reliable benchmarks and faster iteration on LLM performance across various applications.
Pessimistic Outlook
While useful, reliance on automated prompt generation might inadvertently limit the nuanced, human-driven insights often critical for complex LLM behaviors. The cached data policy, even with PII stripping, could raise privacy concerns for sensitive evaluation traces, despite its short retention period.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.