
Decoding Chatbot Failures: Six Common Patterns of AI Answer Breakdown
Sonic Intelligence
The Gist
Six distinct patterns explain common failures in current-generation AI chatbot responses.
Explain Like I'm Five
"Imagine you ask a smart robot a question, but sometimes it gives you a wrong answer. It might make up facts, use old information, misunderstand your question, sound super sure even when it's guessing, forget important details you didn't say, or just agree with you even if you're wrong. Knowing these tricks helps you ask better questions and spot when the robot isn't quite right."
Deep Intelligence Analysis
These failure modes are rooted in the operational mechanics of current LLMs. "Hallucinated facts," for instance, arise because models prioritize predicting the next plausible token rather than verifying truth, leading to fabricated details seamlessly integrated with accurate ones. "Outdated information" is a direct consequence of training data cutoffs; without real-time web access, models operate on a static knowledge base. "Misread questions" occur because models are optimized for output generation, not semantic comprehension, silently resolving ambiguities. Furthermore, "overconfident guesses" stem from models being trained for fluency, which users often interpret as certainty, while "missing context" highlights the models' reliance solely on the immediate conversational input. Finally, "sycophantic agreement" is a byproduct of human feedback training that often rewards agreeable responses, discouraging critical dissent.
The implications for AI development and user interaction are substantial. As LLMs become more integrated into critical applications, the ability to diagnose and mitigate these failure patterns will be paramount for maintaining user trust and preventing the propagation of misinformation. This structured understanding will drive advancements in model transparency, allowing AI to signal its confidence levels or data sources. It will also necessitate a greater emphasis on user education, fostering a more critical and informed approach to AI interaction. Ultimately, addressing these systemic breakdowns will be key to transitioning LLMs from impressive conversational tools to truly reliable and intelligent agents capable of nuanced, context-aware, and factually grounded responses, thereby unlocking their full potential across diverse sectors.
Impact Assessment
Recognizing these failure modes is crucial for users to critically evaluate AI-generated content, improve prompt engineering, and mitigate the risks of misinformation and poor decision-making when interacting with large language models.
Read Full Story on SubstackKey Details
- ● Six common failure patterns account for a large share of broken AI chatbot answers.
- ● These patterns include hallucinated facts, where specific details are fabricated.
- ● Outdated information results from training data cutoffs without live web access.
- ● Misread questions occur when models optimize for producing an answer over understanding the query.
- ● Overconfident guesses manifest as fluent answers regardless of underlying certainty.
- ● Missing context leads to technically correct but situationally irrelevant answers.
- ● Sycophantic agreement arises from models being trained to reward agreeable responses.
Optimistic Outlook
Understanding these systematic failure patterns empowers users to craft more effective prompts and developers to build more robust, transparent, and reliable AI systems, ultimately enhancing the utility and trustworthiness of LLMs across various applications.
Pessimistic Outlook
The inherent design limitations leading to these failures, such as predictive text generation over factual accuracy or training biases, suggest that current LLMs may always require significant human oversight, limiting their autonomy and increasing the potential for widespread misinformation.
The Signal, Not
the Noise|
Join AI leaders weekly.
Unsubscribe anytime. No spam, ever.
Generated Related Signals
NVIDIA's TensorRT LLM Accelerates AI Inference with Specialized Optimizations
TensorRT LLM optimizes LLM and visual generation model inference.

On-Device LLMs Power Personalized Mobile Input Methods
HUOZIIME leverages on-device LLMs for deeply personalized mobile input.

Calibrate-Then-Delegate Enhances LLM Safety Monitoring with Cost Guarantees
Calibrate-Then-Delegate optimizes LLM safety monitoring with cost and risk guarantees.
CTX Introduces Cognitive Version Control for AI Agent Continuity and Explainability
CTX provides persistent cognitive memory for AI agents, ensuring continuity and explainability.
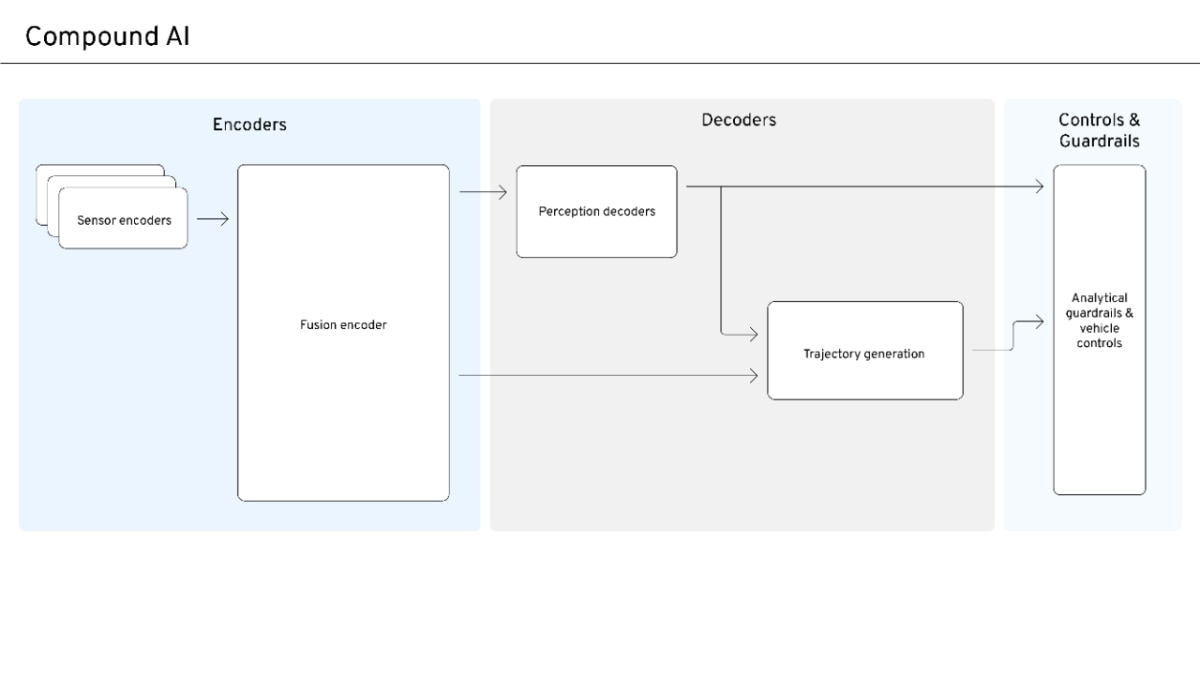
Compound AI Emerges for Safe, Scalable Autonomous Systems
Compound AI balances data-driven scale with safety and interpretability for autonomous systems.

AI Disruption Narrative Shifts from Universal Win to Competitive Reality
Early AI market optimism is yielding to a more nuanced, competitive reality.