Externalization Redefines LLM Agent Architecture
Sonic Intelligence
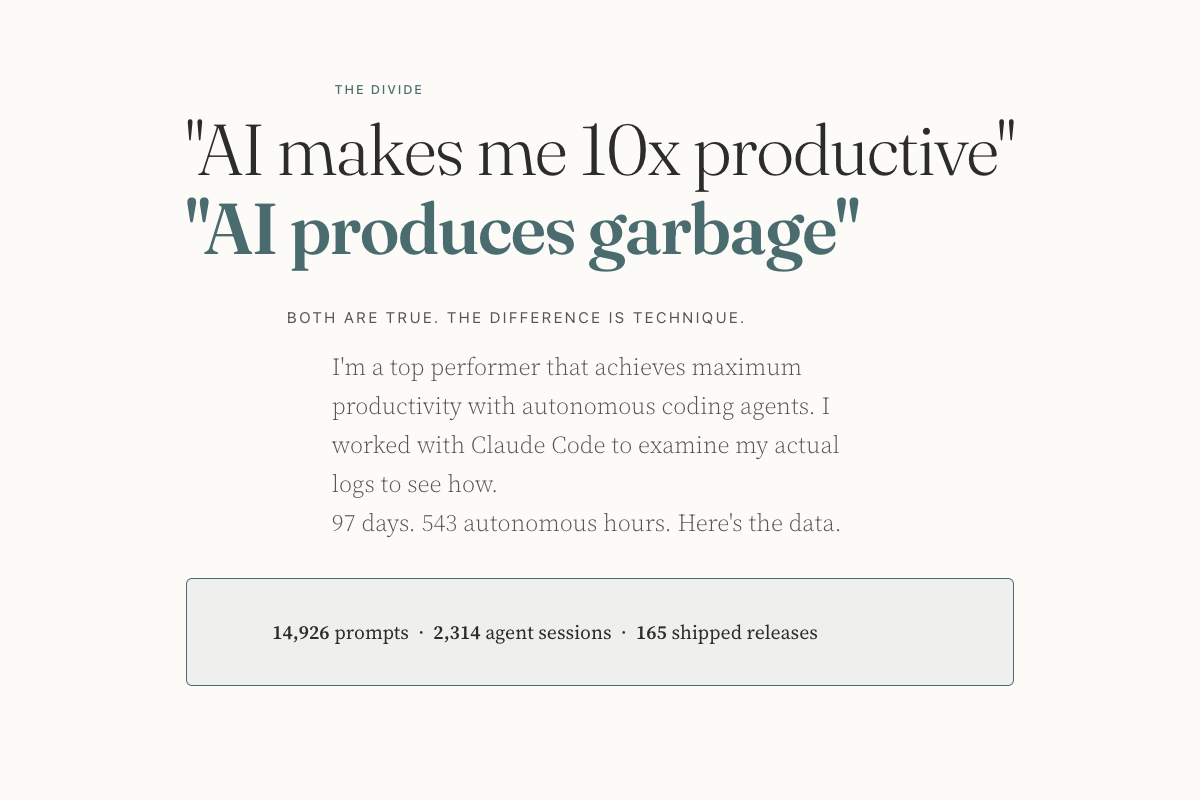
LLM agent capabilities are shifting from internal weights to external infrastructure.
Explain Like I'm Five
"Imagine an AI brain that used to try to remember everything inside itself. Now, it's like the brain has sticky notes for memories, a toolbox for skills, and a rulebook for talking to others. A 'harness' helps it use all these outside tools properly. This makes the AI much better at doing things without getting confused."
Deep Intelligence Analysis
Historically, the progression of AI systems has moved from hard-coded rules to learned parameters (weights), then to contextual prompting, and now towards this externalized harness approach. Key details from the analysis highlight that memory externalizes state across time, skills externalize procedural expertise, and protocols externalize interaction structure, all unified by harness engineering for governed execution. This modularity allows for specialized components to handle specific cognitive functions, enhancing the overall system's robustness. The trade-off between parametric and externalized capability becomes a critical design consideration, influencing efficiency and scalability.
Looking forward, this trend suggests a future where AI agent development will resemble complex software engineering more than pure machine learning research. Emerging directions include self-evolving harnesses and shared agent infrastructure, which could standardize and accelerate the deployment of advanced agents. However, this distributed architecture introduces new challenges in evaluation, governance, and understanding the long-term co-evolution of models and their external support systems. The success of future AI agents will depend on the maturity of this external cognitive infrastructure as much as, if not more than, the underlying LLM itself.
{"metadata": {"ai_detected": true, "model": "Gemini 2.5 Flash", "label": "EU AI Act Art. 50 Compliant"}}
Visual Intelligence
flowchart LR A["LLM Agent"] --> B["External Memory"] A --> C["Reusable Skills"] A --> D["Interaction Protocols"] B --> E["Harness Engineering"] C --> E D --> E E --> F["Governed Execution"]
Auto-generated diagram · AI-interpreted flow
Impact Assessment
This paradigm shift in LLM agent design moves beyond core model improvements, emphasizing the critical role of external infrastructure for practical, reliable, and scalable agent deployment. It highlights that future progress hinges on sophisticated system-level engineering, not just larger models.
Key Details
- LLM agents increasingly rely on external memory stores, reusable skills, and interaction protocols.
- Harness engineering coordinates external modules for reliable execution.
- Externalization transforms complex cognitive burdens into solvable forms for models.
- The architectural shift progresses from model weights to context, then to external harness infrastructure.
- Memory externalizes state, skills externalize procedural expertise, and protocols externalize interaction structure.
Optimistic Outlook
Externalization promises more robust, adaptable, and efficient AI agents by offloading complex tasks to specialized modules. This modular approach could accelerate development, foster innovation in agent infrastructure, and lead to more reliable real-world applications. Shared agent infrastructure could also emerge, standardizing and democratizing advanced agent capabilities.
Pessimistic Outlook
Over-reliance on externalization could introduce new layers of complexity and potential failure points in agent systems. Challenges in evaluating and governing these increasingly distributed architectures may arise, making it harder to ensure safety, transparency, and predictable behavior. The trade-off between parametric and externalized capability also needs careful management to avoid performance bottlenecks or over-engineering.
Get the next signal in your inbox.
One concise weekly briefing with direct source links, fast analysis, and no inbox clutter.
More reporting around this signal.
Related coverage selected to keep the thread going without dropping you into another card wall.